

The way we build AI-powered applications is evolving fast. Azure OpenAI has long been a cornerstone for enterprise AI development, and its Chat Completions API has been the workhorse behind countless copilots, assistants, and intelligent automation workflows (including Microsoft Dynamics 365 Business Central’s own System.AI namespace).
But the landscape has shifted decisively. OpenAI has introduced the Responses API, a next-generation interface that unifies the best of Chat Completions and the Assistants API into a single, stateful, production-grade surface. The recommendation from both OpenAI and Microsoft is unambiguous: the Responses API is now the default and recommended approach for all new AI projects.
The Responses API contains several benefits over Chat Completions:
- Better performance: Using reasoning models, like GPT-5, with Responses API will result in better model intelligence when compared to Chat Completions.
- Agentic by default: The Responses API is an agentic loop, allowing the model to call multiple tools, like
web_search,image_generation,file_search,code_interpreter, remote MCP servers, as well as your own custom functions, within the span of one API request. - Lower costs: Results in lower costs due to improved cache utilization (40% to 80% improvement when compared to Chat Completions).
- Stateful context: Use
store: trueto maintain state from turn to turn, preserving reasoning and tool context from turn-to-turn. - Flexible inputs: Pass a string with input or a list of messages; use instructions for system-level guidance.
- Encrypted reasoning: Opt-out of statefulness while still benefiting from advanced reasoning.
- Future-proof: Future-proofed for upcoming models.
The two APIs side by side: a first look.
Before diving into the architectural reasoning, it is worth seeing the two APIs next to each other in their most direct form: a raw REST call.
Chat Completions: a multi-turn conversation:
With Chat Completions, starting a conversation and then following up on it requires two entirely separate requests. In the second request, you must manually include everything that happened in the first (the original system message, the user’s question, and the assistant’s answer) as if the service has never heard of you before.
First turn:
POST https://YOUR-RESOURCE.openai.azure.com/openai/deployments/gpt-4o/chat/completions?api-version=2024-10-21
Content-Type: application/json
api-key: YOUR-API-KEY
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant specializing in financial analysis."
},
{
"role": "user",
"content": "What are the main risks of rising interest rates for a manufacturing company?"
}
],
"max_tokens": 500,
"temperature": 0.7
}
The response comes back with the assistant’s answer. Now, to ask a follow-up, you must build the second request by repeating the full conversation history and appending the new user message:
POST https://YOUR-RESOURCE.openai.azure.com/openai/deployments/gpt-4o/chat/completions?api-version=2024-10-21
Content-Type: application/json
api-key: YOUR-API-KEY
{
"messages": [
{
"role": "system",
"content": "You are a helpful assistant specializing in financial analysis."
},
{
"role": "user",
"content": "What are the main risks of rising interest rates for a manufacturing company?"
},
{
"role": "assistant",
"content": "Rising interest rates primarily affect manufacturing companies through higher borrowing costs, which increase the expense of financing capital investments and working capital..."
},
{
"role": "user",
"content": "How should the company hedge against those risks?"
}
],
"max_tokens": 500,
"temperature": 0.7
}
Every turn adds more to the payload. By turn ten, you are sending nine prior exchanges on every request — paying for tokens you have already paid for before.
Responses API: A multi-turn conversation:
With the Responses API, the first request looks simpler, there is no need to declare a messages array with roles. You send an input string or a lightweight message object, and the service returns a response with a unique ID:
POST https://YOUR-RESOURCE.openai.azure.com/openai/v1/responses
Content-Type: application/json
api-key: YOUR-API-KEY
{
"model": "gpt-4o",
"instructions": "You are a helpful assistant specializing in financial analysis.",
"input": "What are the main risks of rising interest rates for a manufacturing company?"
}
The response comes back as a structured object with an id field, for example, resp_8a3f2c1d9b4e. Now the follow-up request is strikingly different. Instead of resending the entire conversation history, you reference the previous response by its ID and send only the new message:
POST https://YOUR-RESOURCE.openai.azure.com/openai/v1/responses
Content-Type: application/json
api-key: YOUR-API-KEY
{
"model": "gpt-4o",
"previous_response_id": "resp_8a3f2c1d9b4e",
"input": [
{
"role": "user",
"content": "How should the company hedge against those risks?"
}
]
}
The server already has the full context of the first exchange. The second request carries only what is genuinely new. As the conversation grows deeper, the payload stays lean (it never carries accumulated history). The service does that work for you.
You can also retrieve any response at any point by its ID:
GET https://YOUR-RESOURCE.openai.azure.com/openai/v1/responses/resp_8a3f2c1d9b4e
api-key: YOUR-API-KEY
And if you no longer need it, you can explicitly delete it:
DELETE https://YOUR-RESOURCE.openai.azure.com/openai/v1/responses/resp_8a3f2c1d9b4e
api-key: YOUR-API-KEY
This lifecycle management (create, retrieve, chain, delete) has no equivalent in Chat Completions. Every response in Chat Completions is ephemeral: once the HTTP response closes, the service forgets it entirely.
The Chat Completions model: powerful but stateless.
Chat Completions works on a strict request-response model. Every call to /chat/completions is entirely self-contained. The API has no memory of previous interactions (it knows only what you send in that specific request). This means the client application is fully responsible for maintaining conversation history. If a user asks a follow-up question, the developer must collect every prior message (user inputs and assistant responses) serialize the entire conversation, and transmit it again with the new request.
This design is simple and predictable, which is part of why it became so widely adopted. But simplicity comes at a cost that compounds as conversations grow longer. Every additional turn adds more tokens to the history payload. On turn 10 of a conversation, you are paying to send tokens 1 through 9 again, just to give the model the context it needs. On turn 20, you send tokens 1 through 19. The cost of a conversation does not grow linearly with turns, it grows quadratically with the total volume of exchange. For a long-running analytical task or a deeply contextual workflow, this becomes both expensive and logistically complex to manage on the client side.
There is also a reliability dimension. When conversation state lives entirely on the client, it can be lost if the client crashes, if the user navigates away, or if the application is rebuilt between sessions.
Resuming a conversation from where it left off requires the application to have persisted and retrieved the full message array, logic that every developer building multi-turn interactions must implement themselves, from scratch, every time.
The Responses API: state lives on the server.
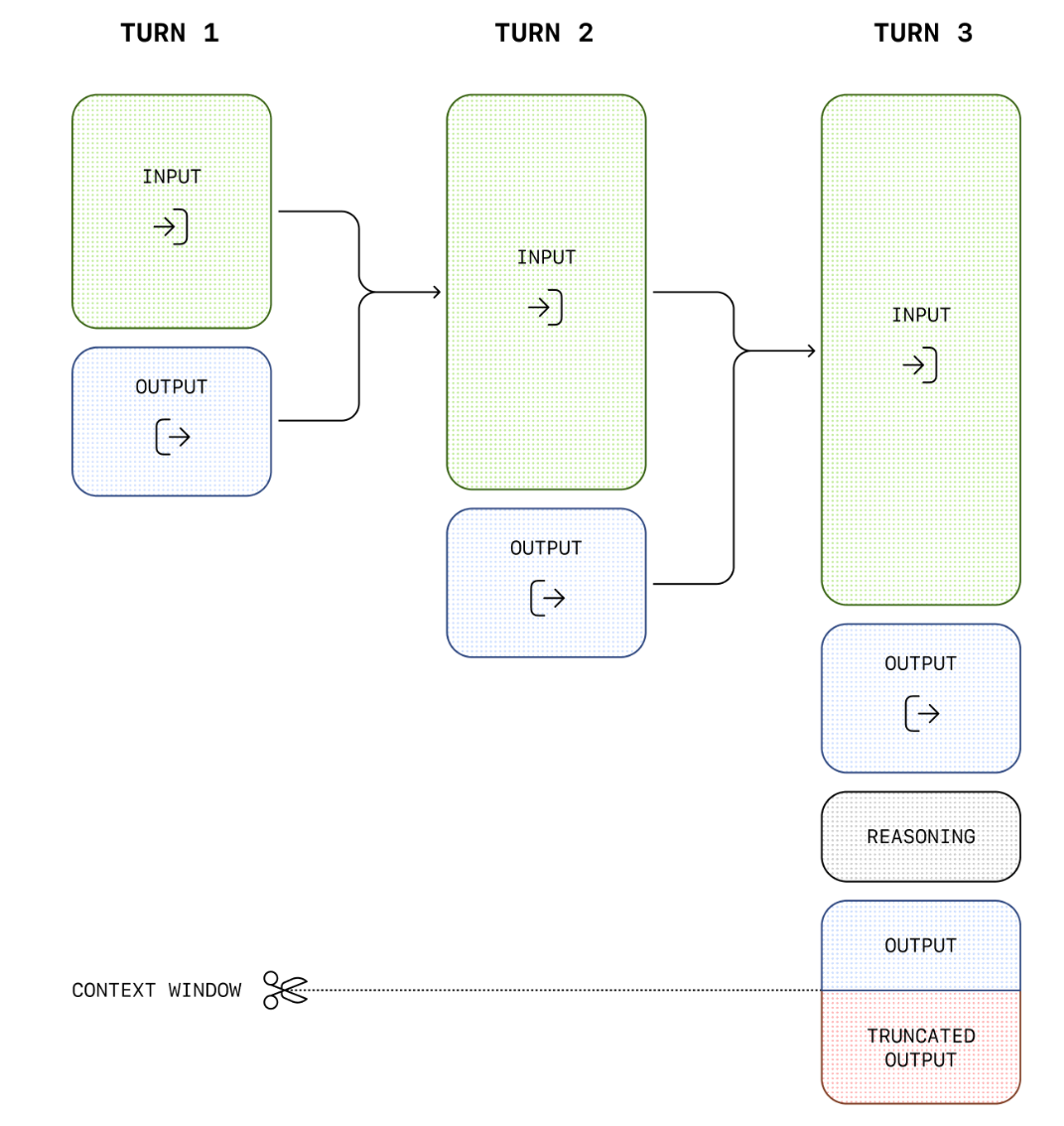
The Responses API changes the fundamental architecture. When you call client.responses.create(), you receive back not just a text completion but a Response object, a persistent, server-side entity with its own unique identifier, status, creation timestamp, and full input/output record.
Because the response is stored server-side for up to 30 days, you can retrieve it at any point by ID, inspect its status, or build on top of it. More importantly, you can chain responses together: when you want to continue a conversation, you pass the previous_response_id parameter, and the server reconstructs the full prior context automatically. Your new request needs only to carry the latest user message. The accumulated history is handled entirely on the platform’s side.
The contrast with Chat Completions is clear. Where Chat Completions forces every client to become a state management system, the Responses API delegates that responsibility to the service. The developer’s code becomes dramatically simpler, and the token cost of multi-turn conversations no longer grows with every exchange. You pay for what is new, not for what you have already sent before.
This is not merely a convenience improvement. It is an architectural shift with significant implications for how we design AI-powered features, particularly in enterprise contexts where conversations can be long, workflows can span hours, and reliability requirements are high (I talked about these topics on some short posts on socials days ago).
Comparing the two approaches: where the advantages are concrete?
The most immediate advantage of the Responses API is token efficiency in multi-turn conversations. With Chat Completions, a 20-turn conversation requires the client to send increasingly large payloads — the full accumulated history on every request. With the Responses API, each follow-up sends only the new message. The server already has everything else. For high-frequency or high-turn applications, this alone can reduce Azure OpenAI costs substantially.
The second major advantage is conversation reliability and resumability. In Chat Completions, if the state is lost (whether due to a client crash, a session expiry, or a network failure) the conversation is gone. Resuming it requires the application to have proactively persisted the full message array somewhere durable. The Responses API eliminates this problem entirely. Because every response is a first-class server-side object with a retrievable ID, any application (or any user session) can resume exactly where it left off simply by referencing that ID.
Third, the Responses API introduces context compaction, a capability with no equivalent in Chat Completions. As conversations grow very long, the API can condense prior context into a compressed representation that preserves the semantic meaning of the exchange while consuming far fewer tokens. This compaction can be triggered manually by the developer, or it can be configured to happen automatically on the server side when the conversation crosses a token threshold. Either way, the result is that even extremely long interactions (multi-hour agentic workflows, large document analysis chains, complex iterative reasoning tasks) remain tractable and affordable without the developer having to manually prune or summarize the history.
Fourth, the Responses API supports a background execution mode for long-running operations. With Chat Completions, a request that takes a long time to complete holds the HTTP connection open and blocks the calling thread. If the connection drops, the response is lost. The Responses API’s background mode decouples invocation from completion: you fire the request, receive a response ID immediately, and poll for the result when convenient. This is a fundamental enabler for agentic workflows in enterprise settings, where tasks may take minutes rather than seconds.
Fifth, the Responses API provides richer streaming event types. Chat Completions supports streaming via Server-Sent Events, but the event model is relatively coarse (you get chunks of text as they arrive).
The Responses API defines a richer set of named events: response.created, response.output_item.added, response.output_item.done, response.completed, and others. This granularity makes it far easier to build responsive, observable streaming experiences, for example tracking exactly when a tool call starts and finishes within a streamed agentic response, or displaying progress indicators during complex multi-step reasoning.
Finally, the Responses API is the only gateway to certain new capabilities. The computer-use-preview model, which powers autonomous computer interaction, is only accessible through the Responses API. As Microsoft continues to release new frontier models and capabilities, the Responses API is the surface through which they will be exposed first. Chat Completions is not being retired, but it is not where innovation is concentrated.
The stateless option still exists.
It is worth noting explicitly that with the Responses API is not a mandate to use server-side state. You can call it with store=false and it behaves as a stateless request (semantically equivalent to Chat Completions), but with access to all of the Responses API’s other capabilities. This means there is no scenario where Chat Completions is uniquely capable that the Responses API cannot serve. The Responses API is a strict superset.
Business Central and the System.AI namespace: the current state.
Microsoft Dynamics 365 Business Central has built its AI extensibility model around the System.AI namespace, part of the System Application. This namespace gives AL developers access to Azure OpenAI capabilities through a set of purpose-built objects: the AzureOpenAI codeunit as the central orchestrator, AOAI Chat Messages for constructing the conversation history, AOAI Chat Completion Params for controlling generation parameters like temperature and max tokens, and AOAI Operation Response for inspecting results.
The current model type exposed by the AOAI Model Type enum covers Text Completions, Chat Completions, and Embeddings.
For Copilot capability development in Business Central today, partners use Chat Completions. The developer constructs a system message (the metaprompt), adds user messages describing the task, calls GenerateChatCompletion, and reads back the last message from the chat history. Everything is client-side: the AL extension builds and owns the entire message array.
What the System.AI module does exceptionally well is everything above and beyond the raw API call:
- It provides built-in prompt guardrails to reduce the risk of generating harmful or off-topic content.
- It surfaces Copilot capabilities in a unified discoverability layer so users can find, enable, and govern AI features across the system.
- It emits telemetry automatically, giving administrators and partners visibility into AI usage without writing additional instrumentation code.
- It provides a managed resource model where Microsoft handles Azure OpenAI endpoint management and billing transparently (partners do not need to provision or manage their own Azure OpenAI subscriptions for customer-facing scenarios).
These abstractions are for sure significant advantages for partners, that don’t need to write tons of code to do such things.
Where is the current gap?
The architectural reality is that Business Central’s System.AI namespace currently wraps the Chat Completions API. This is a deliberate and reasonable design decision: Chat Completions was the mature, stable foundation available when the System Application’s AI module was built, and it serves the majority of current Business Central Copilot scenarios very well.
But as the Responses API matures and as AI scenarios in Business Central become more ambitious, the limitations of the Chat Completions foundation will become more visible.
Consider a Copilot feature that must reason across an entire purchase order backlog, iterating through dozens of vendor records over multiple steps. Or a document intelligence feature that analyzes a long contract with many follow-up clarifications. Or an autonomous agent that orchestrates corrections across multiple Business Central tables in a background process. These are exactly the scenarios where server-side state management, context compaction, and background execution mode provide decisive advantages, advantages that are not available through the current System.AI surface.
The AOAI Model Type enum’s design is extensible. The AzureOpenAI codeunit’s abstraction pattern is capable of evolving. When Microsoft updates System.AI to also expose Responses API capabilities, the underlying platform will be ready for it.
What this means for Business Central developers today?
The practical guidance for Business Central developers building Copilot features now is straightforward: continue using the System.AI namespace and Chat Completions. The platform’s guardrails, telemetry, managed resources, and capability governance model are worth far more than the raw API flexibility you would gain by bypassing System.AI and calling the Responses API directly. Business Central’s Copilot features today (text suggestions, document summarization, email drafting etc.) are well-served by Chat Completions, and System.AI wraps that capability elegantly.
What matters most right now is understanding the Responses API conceptually, so that when the System Application evolves to expose its capabilities, you are not learning a new paradigm under time pressure.
To support the new Responses API in Business Central, Microsoft could extend the AOAI Model Type enum with a new Responses value, signaling to the AzureOpenAI codeunit which API surface to invoke.
Alongside it, a new GenerateResponse method on the AzureOpenAI codeunit would replace the need for GenerateChatCompletion in stateful scenarios (the caller passes an input message and the platform handles conversation history entirely).
Supporting that generation method, Microsoft would probably need two new codeunits:
- An
AOAI Responsecodeunit would expose the richer response shape of the Responses API: response ID, status, output text, and the previous response ID link. - An
AOAI Response Paramscodeunit would expose the new parameters that make the Responses API powerful:SetPreviousResponseIdfor conversation chaining,SetStorefor stateless operation,SetContextManagementfor automatic compaction, andSetBackgroundfor long-running async execution.
Beyond the raw API surface, Microsoft should bridge the Responses API’s background execution mode to the existing Job Queue/background processing infrastructure, enabling AL extensions to fire long-running AI tasks asynchronously and retrieve results when complete, without blocking a user session. This alone would unlock lots of complex agentic Copilot scenarios inside Business Central.
I think that the existing System.AI design is already well-suited to this evolution. It is an extension of a foundation built with future growth in mind.
For modern and complex AI features (inside or outside Business Central) start thinking on adopting Responses API from the beginning because advantages on complex agentic scenarios are a lot.
Conclusion
The Responses API is not a small incremental update to Azure OpenAI. It is a rethinking of where responsibility lives in AI application architecture.
By moving conversation state, context management, and response lifecycle from client to server, it eliminates entire categories of complexity that Chat Completions leaves to the developer. It makes multi-turn conversations dramatically more token-efficient, more resilient, and more capable of scaling to the kinds of long-running agentic tasks that represent the frontier of enterprise AI.
Chat Completions was the right tool for the first generation of AI-integrated applications. The Responses API is the right tool for what comes next. For new Azure OpenAI projects, my suggestion is: if you can, start with the Responses API. For Business Central developers working within the System.AI namespace, the platform will evolve to bring these capabilities forward for sure.
