


This post is my contribution to the Azure Spring Clean 2024 event, an initiative to promote well managed Azure tenants.
Azure OpenAI Service provides REST API access to OpenAI’s powerful language models including the GPT-4, GPT-4 Turbo with Vision, GPT-3.5-Turbo, and Embeddings model series.
These models can be easily adapted to your specific task including but not limited to content generation, summarization, image understanding, semantic search, and natural language to code translation.
Using Azure OpenAI service for integrating Generative AI features into your solutions is quite easy:
- Create an instance of the Azure OpenAI service
- Deploy an AI model
- Start using it by sending prompts and receiving responses.
Now imagine that you’ve created your solution with lots of exciting AI features. The demo for your customers was a great success, everyone agree to have these AI features moved to production and available for all.
And all your users start using your AI features heavily… prompt… prompt.. prompt… completions… completions… completions… and then… CRASH!! 😦
The Azure OpenAI service has quotas and operational limits that must be respected. More in details, you have a maximum prompt tokens per request and maximum number of token per minutes that can be sent to the model.
When you have a lot of users using your Generative AI features continuously and so sending a lot of requests to your Azure OpenAI instance, the service request could fail because the provisioned service could be unavailable due to rate limit. Another possible problem could be that your Azure OpenAI instance could be down for some reasons and this can affect the availability of your AI functionalities.
In simple words: using a single Azure OpenAI instance could not be the best choice in a real-world scenario.
Azure OpenAI permits you to deploy multiple service instances in multiple regions and having a load-balancing system in-place able to forward the requests coming from the application features to the various instances could be a great choice in order to provide redundancy and guarantee service availability.
How to load-balance Azure OpenAI service requests?
There are different ways to load-balance service requests between different Azure OpenAI instances (using Front Door, using Application Gateway etc) but an easy and cost-effective way to do that can be done by using Azure API Management, an Azure service that offers a scalable, multi-cloud API management platform for securing, publishing, and monitoring your APIs (I’ve talked about this service in the past for various scenarios in my blog).
The scenario to be enterprise-ready with Azure OpenAI is to move from the following solution (business application sending AI requests to a single Azure OpenAI instance):
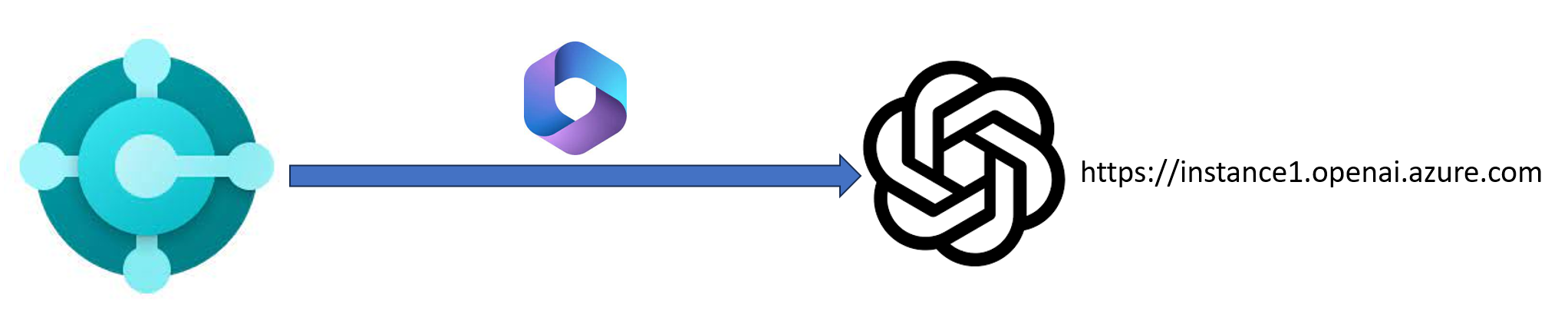
to the following solution:
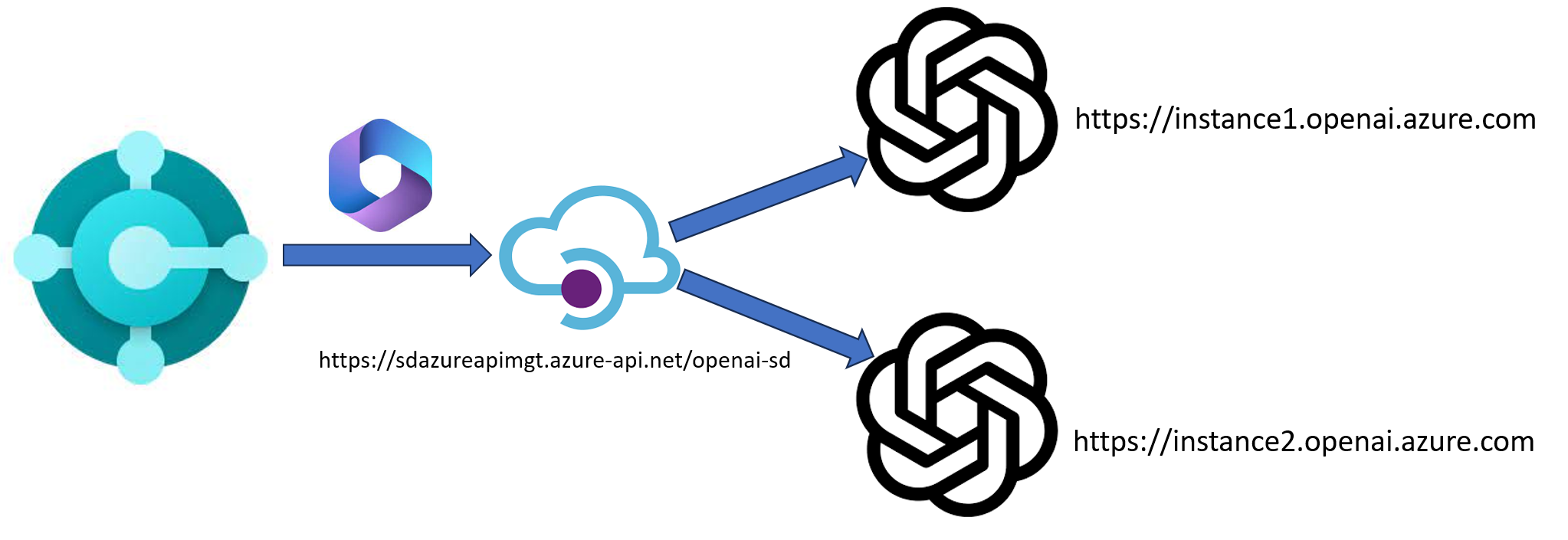
As you can see, here we have deployed different Azure OpenAI instances. Instead of direct calling a single Azure OpenAI instance, to avoid scalability problems and to have redundancy of the service, in this scenario all AI requests coming from our business application are sent to an Azure API Management unique endpoint. Then Azure API Management redirects the requests to the various Azure OpenAI instances accordingly to a routing criteria (and handling the needed authentication securely).
Let’s see how we can create an architecture like in the above diagram.
At first, you need to have an instance of the Azure API Management service deployed in your Azure subscription (informations on how to do that can be found here).
When the Azure API Management service is provisioned, select APIs and then add a new API by selecting the manual definition (HTTP):

Then create a new HTTP API by filling the Display name and Name fields:
Here you can see the Base URL of your APIs (the API Management url shared with all your APIs defined inside the Azure API Management instance).
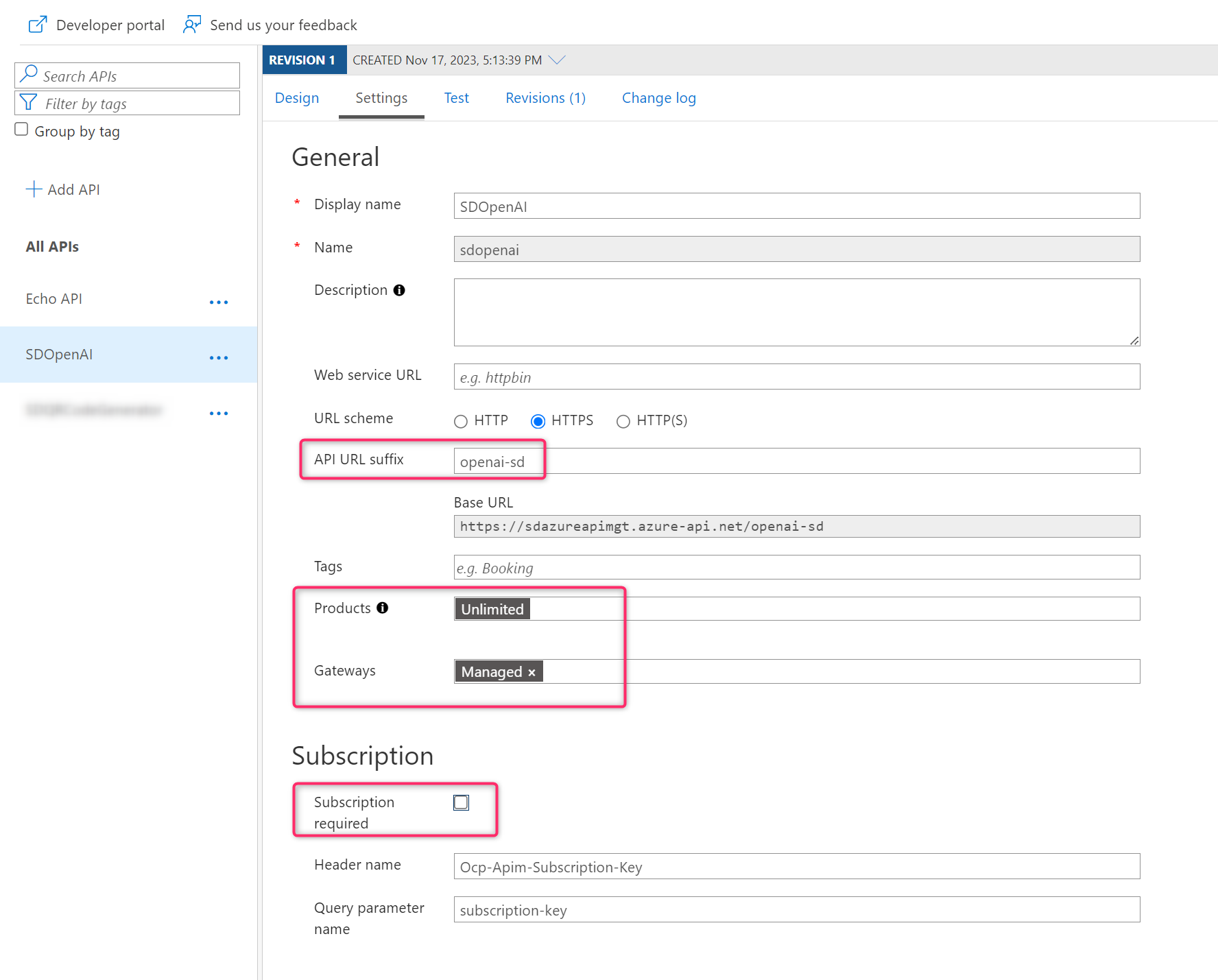
Then select the Settings tab and here:
- Set URL scheme to HTTPS.
- Specify an API URL suffix (it will make your endpoint unique for Azure OpenAI).
- Set Products to Unlimited.
- Set Gateways to Managed.
- Uncheck the Subscription required flag (API keys will be handled in a different way later).
In order to define APIs in Azure API Management, we need to define the frontend (API methods and URLs), the inbound processing (how the request is handled before it’s sent to the backend), the backend (the endpoint to call) and the outbound processing (how the response must be handled before it’s sent to the caller). These are the components of an API definition.
Let’s start with the frontend.
From your API definition, under the Design tab select Add operation. Here we need to define the methods of our APIs. Here I want to insert into Azure API Management a “wrapper” for calling the Azure OpenAI Chat completions API (API that creates chat competions for prompts with the GPT-35-Turbo and GPT-4 models). This API can be invoked by sending a POST request to the following Azure OpenAI endpoint:
POST https://{your-resource-name}.openai.azure.com/openai/deployments/{deployment-id}/chat/completions?api-version={api-version}
To do that, add a POST method with the following url (see image below):
/openai/deployments/{deployment}/chat/completions
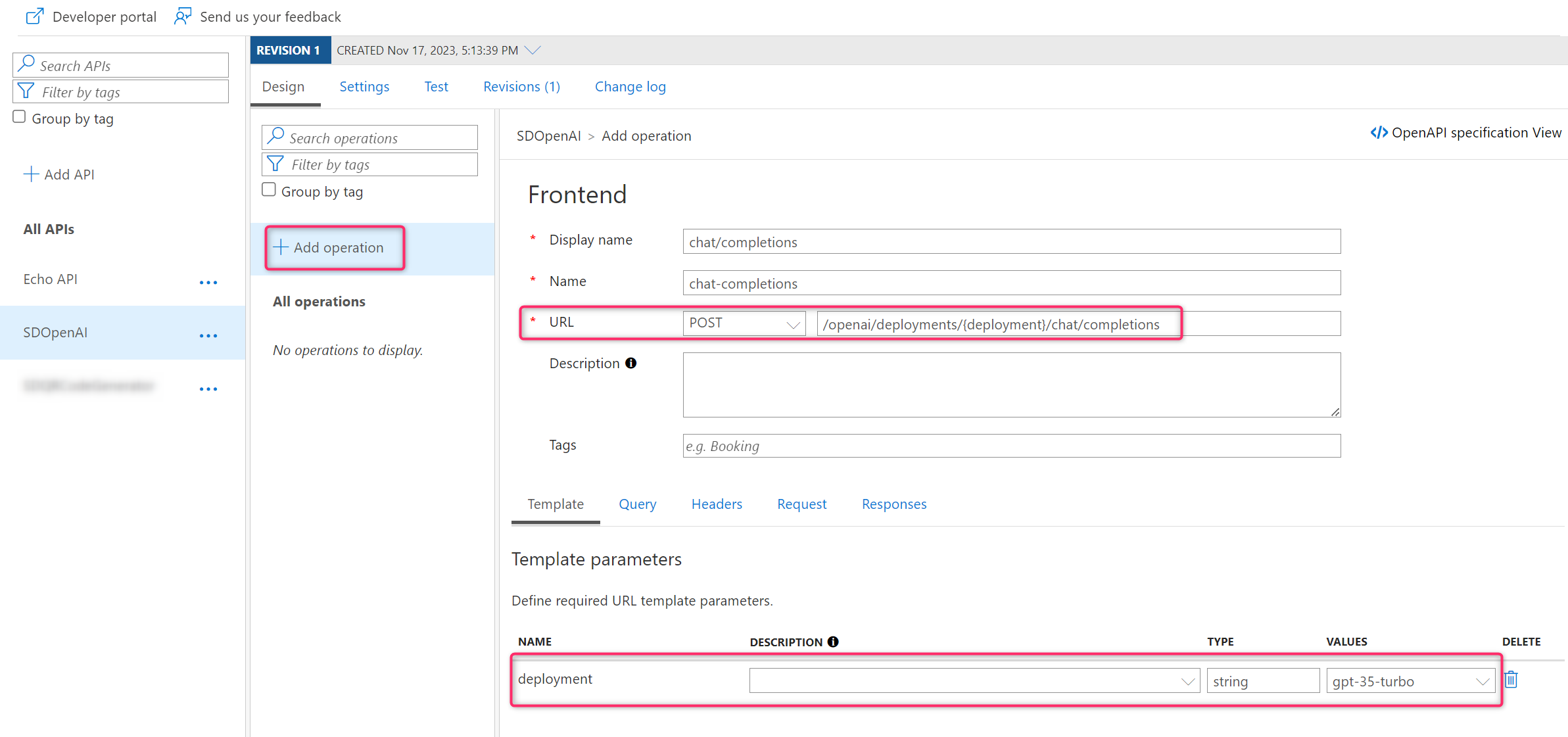
{deployment} is a string variable that will contain the deployed AI model name (in my case it’s gpt-35-turbo).
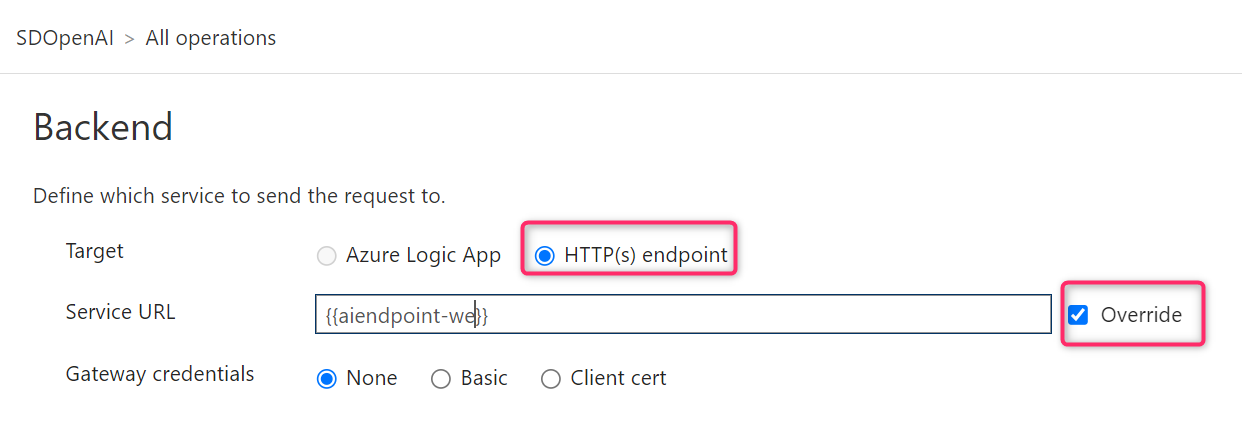
When the endpoint is created, from the Design tab of our API definition now select Backend and click on HTTP(s) endpoint:

Here is where we define the Azure OpenAI API endpoints to call. Set Target = HTTPS and Service URL = url your Azure OpenAI endpoint. Check also the Override flag (see image below):

When the backend is created, we have defined a “bridge” between our Azure API Management instance and the real Azure OpenAI endpoint. In my scenario here, this means that to call the Azure OpenAI Chat Completions API, instead of sending a POST request to the following direct URL:
https://sdtechdaysai.openai.azure.com/openai/deployments/gpt-35-turbo/chat/completions?api-version=2023-07-01-preview
I can now send a POST request to the Azure API Management endpoint:
https://sdazureapimgt.azure-api.net/openai-sd/openai/deployments/gpt-35-turbo/chat/completions?api-version=2023-07-01-preview
To test if it works, I’m sending the POST request to the above endpoint by using CURL:
curl "https://sdazureapimgt.azure-api.net/openai-sd/openai/deployments/gpt-35-turbo/chat/completions?api-version=2023-07-01-preview" \
-H "Content-Type: application/json" \
-H "api-key: MYAPIKEY" \
-d '{
"messages": [{"role": "user", "content": "Tell me something about Azure OpenAI Service."}]
}'
and here is the answer:

I’m able to call my Azure OpenAI model by passing through the Azure API Management endpoint. Wonderful…
But here there’s a problem… the authentication!
Here I’m passing the api-key parameter required by Azure OpenAI in the HTTP request itself. This is perfect if I’m working with a single Azure OpenAI instance, but the goal of this post is to have N Azure OpenAI instances and then to redirect the HTTP requests to the various instances dinamically, where the api-key parameter is different between instances.
To store the api keys for the various Azure OpenAI instances we can use Azure API Management Named values. Named values are a global collection of name/value pairs in each API Management instance that can be used to manage constant string values and secrets across all API configurations and policies:
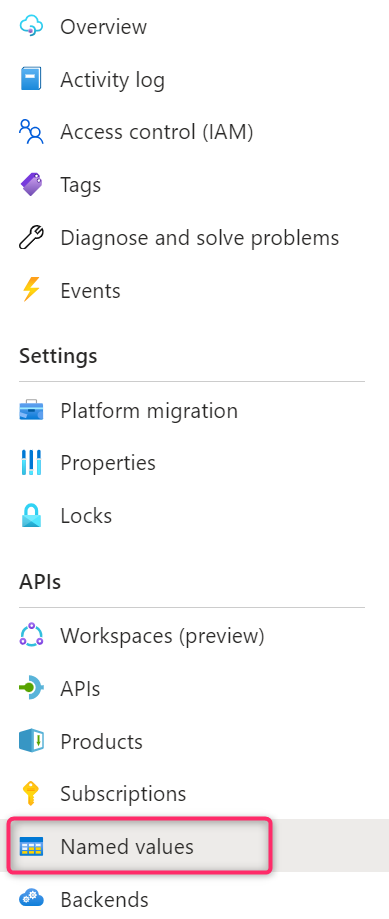
To handle our api keys, we need to create a Named value entry for each of the Azure OpenAI instances, like in the following image:

Here I’ve created a named value called aiendpoint-we (Type = Plain text) containing the endpoint of my first Azure OpenAI instance (located in Western Europe). Then I repeat the same for the second Azure OpenAI instance (in my case it’s located in East US):
The same can be done for handling the various api keys. For that I create a named value with Type = Secret for each api key, liker in the following image:

Here I’ve defined a secret key called aiendpoint-we-key containing the api key for the first Azure OpenAI endpoint. You need to do that also for the other endpoints you have (in my case I’ve created also a aiendpoint-us-key named value containing the api key of my second Azure OpenAI endpoint).
I can then go to the API backend definition and change the Service URL and pointing it to the previously defined named values by using the following notation: {{Named_Value_Name}}:
Now we need to pass the previously defined api keys variables in the header of the HTTP request in order to be able to call Azure OpenAI correctly. To do that, we need to go into the Inbound processing section and then click on Policies:

In Azure API Management, API publishers can change API behavior through configuration using policies. Policies are a collection of statements that are run sequentially on the request or response of an API. Policies are applied inside the gateway between the API consumer and the managed API. While the gateway receives requests and forwards them, unaltered, to the underlying API, a policy can apply changes to both the inbound request and outbound response.
The inbound processing policy is used to modify the request before it is sent to the backend service. We can inject the api key by using the following inbound policy definition:
<policies>
<inbound>
<base />
<set-backend-service base-url="{{aiendpoint-we}}" />
<set-header name="api-key" exists-action="override">
<value>{{aiendpoint-we-key}}</value>
</set-header>
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
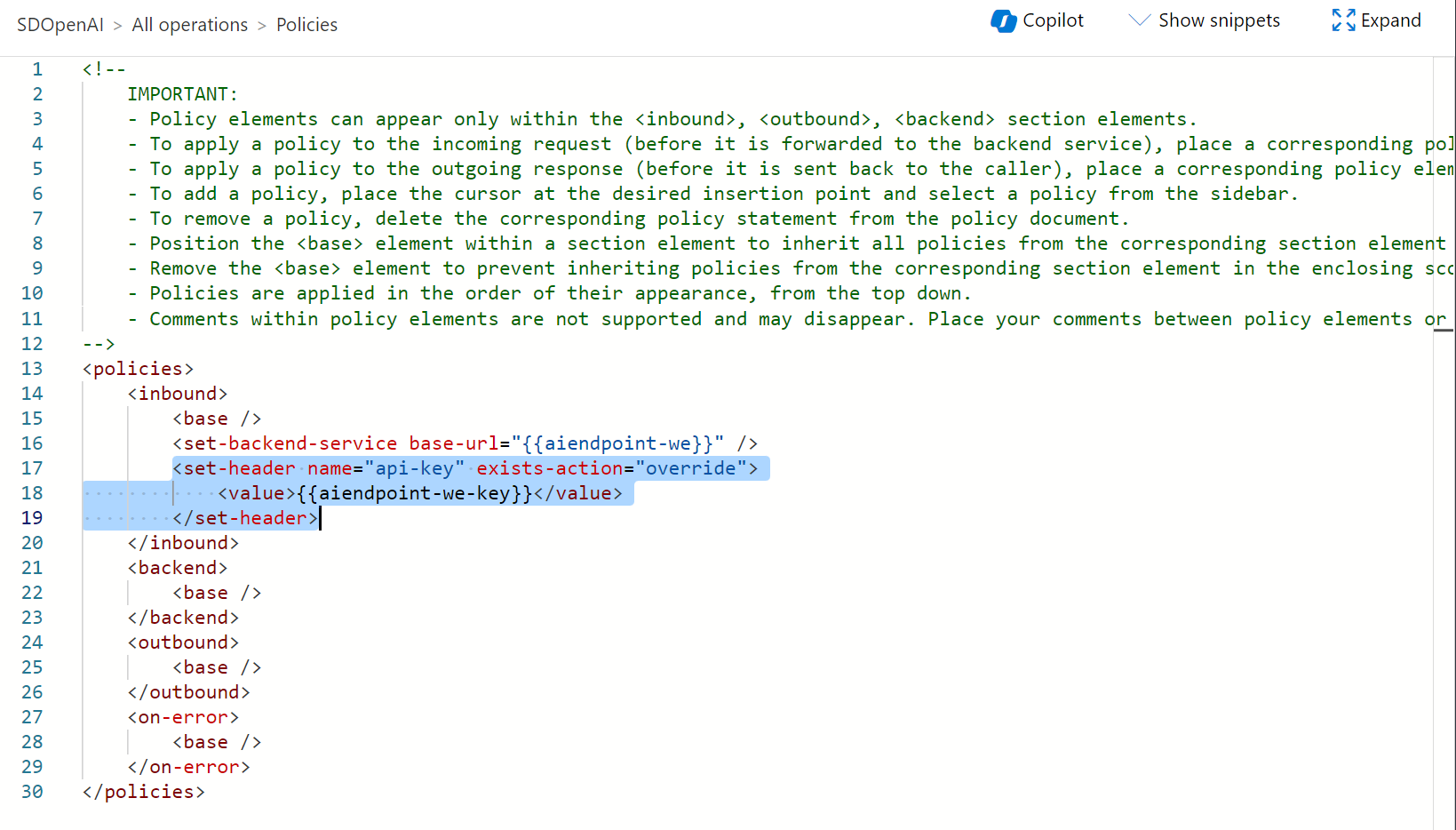
With the above policy, when a request is sent to the Azure API Management endpoint (our unique endpoint for accessin Azure OpenAI) the policy sets the backed service url and inserts the api-key parameter (with its appropriate value) in the request header. Values are taken from the named values parameters previously created.
What happens now?
I can now send a POST request to the unique Azure API Management endpoint without passing credentials and all will be handled by Azure API Management itself (request is routed to the right Azure OpenAI instance with the right authentication key):
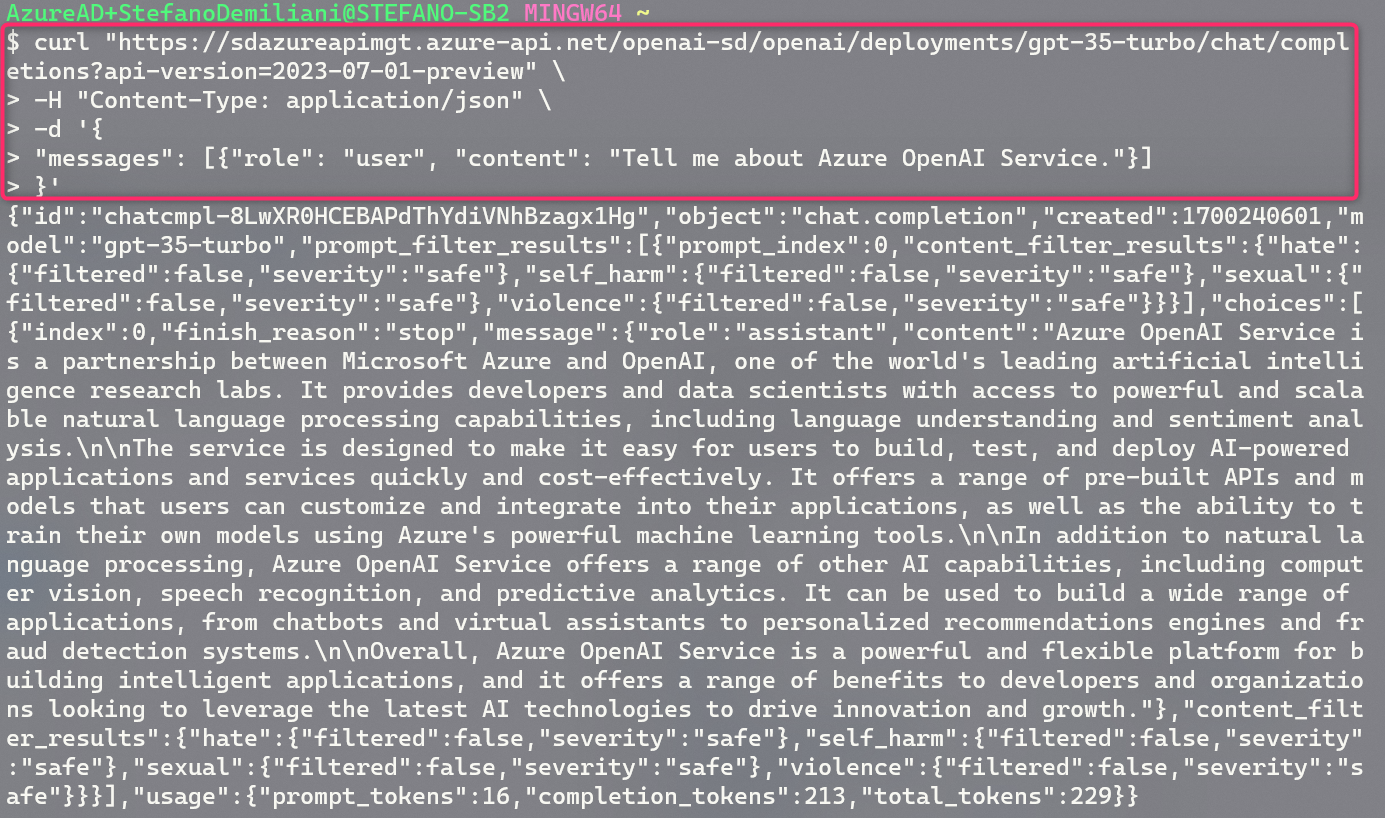
As you can see from the above image, I’m not passing any type of credentials now and my Azure OpenAI model is responding correctly.
Handling load balancing
Now we need to handle the load balancing of HTTP requests between the various Azure OpenAI instances. We can do that again by using the Inbound processing policy. Here we can have differen type of logic to route requests between endpoint.
Here I’ve used the following policy:
<policies>
<inbound>
<base />
<set-variable name="rand" value="@(new Random().Next(0, 2))" />
<choose>
<when condition="@(context.Variables.GetValueOrDefault<int>("rand") <= 1)">
<set-backend-service base-url="{{aiendpoint-we}}" />
<set-header name="api-key" exists-action="override">
<value>{{aiendpoint-we-key}}</value>
</set-header>
</when>
<when condition="@(context.Variables.GetValueOrDefault<int>("rand") > 1)">
<set-backend-service base-url="{{aiendpoint-us}}" />
<set-header name="api-key" exists-action="override">
<value>{{aiendpoint-us-key}}</value>
</set-header>
</when>
<otherwise />
</choose>
</inbound>
<backend>
<base />
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
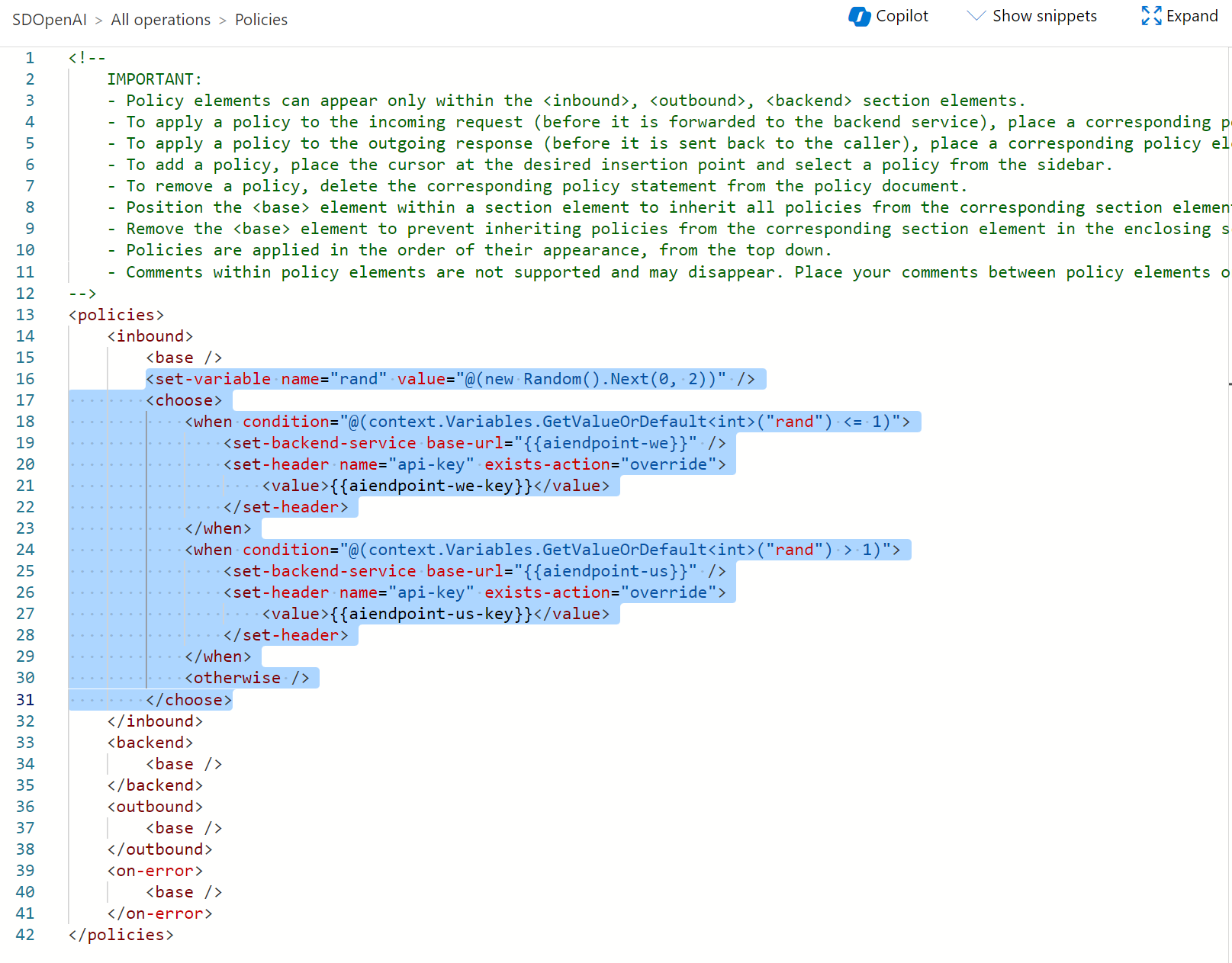
What does this policy do?
It simply generates a random number between 0 and 2. If the generated number is <=1 then the request is sent to the first Azure OpenAI endpoint (ai-endpoint-we), otherwise the request is sent to the second Azure OpenAI endpoint (ai-endpoint-us).
In this way we’re transparently load balancing requests coming from our AI feature between N different Azure OpenAI endpoints (2 in my case) and this assures more reliability.
From AL code, you can call the global endpoint without passing any authentication key and all will be managed for you.
Handling retries.
In order to guarantee reliability of your AI features, you can also handle a retry policy if something in the backed occurs. You can handle the retry policy by adding a retry condition block in the backend node of your inbound policy as follows:
<policies>
<inbound>
<base />
<set-variable name="rand" value="@(new Random().Next(0, 2))" />
<choose>
<when condition="@(context.Variables.GetValueOrDefault<int>("rand") <= 1)">
<set-backend-service base-url="{{aiendpoint-we}}" />
<set-header name="api-key" exists-action="override">
<value>{{aiendpoint-we-key}}</value>
</set-header>
</when>
<when condition="@(context.Variables.GetValueOrDefault<int>("rand") > 1)">
<set-backend-service base-url="{{aiendpoint-us}}" />
<set-header name="api-key" exists-action="override">
<value>{{aiendpoint-us-key}}</value>
</set-header>
</when>
<otherwise />
</choose>
</inbound>
<backend>
<retry condition="@(context.Response.StatusCode >= 300)" count="3" interval="1" max-interval="10" delta="1">
<choose>
<when condition="@(context.Response != null && (context.Response.StatusCode >= 300))">
<set-variable name="rand" value="@(new Random().Next(0, 2))" />
<choose>
<when condition="@(context.Variables.GetValueOrDefault<int>("rand") <= 0)">
<set-backend-service base-url="{{aiendpoint-we}}" />
</when>
<when condition="@(context.Variables.GetValueOrDefault<int>("rand") > 1)">
<set-backend-service base-url="{{aiendpoint-us}}" />
</when>
<otherwise />
</choose>
</when>
<otherwise />
</choose>
<forward-request buffer-request-body="true" buffer-response="false" />
</retry>
</backend>
<outbound>
<base />
</outbound>
<on-error>
<base />
</on-error>
</policies>
Here the <retry> block specifies that a retry will be performed up to 3 times if the backend HTTP status code is > = 300. After these, only if the backend then fails again, a random number is generated as previously explained in order to determine the next available backend service.
Conclusion
Generative AI features in business applications are cool, but you need to remember that if you want to introduce your own AI features into your solutions you need to check for the operational limits of the Azure OpenAI service and act accordingly. A solution that works with 10 users using an AI model could not work if users are 100…
