

Last week I wrote a post providing a solution for interacting with files saved in an FTP server directly from Dynamics 365 Business Central SaaS.
As said at the beginning of that post, the solution was “what I think it’s one of the best solutions in terms of performances, scalability and reliability” and what we currently use on different cloud projects when we need to handle large files.
Someone of you asked me why I’m using an Azure Function for handling the parsing of the uploaded files and not directly a full low code approach. The main response to this question is essentially one: PERFORMANCE!
As said on that post or in the comments I’ve shared with some of you on Linkedin or privately, if you’re handling small and not so complex files, a full low code approach could be a possible solution absolutely, but if you need to handle complex file formats or very large files, the low code approach is absolutely not the best solution to adopt (I’ve also shared with you some real world data where a serverless workflow was moved from hours of executions to minutes only by using an Azure Function for complex file parsing).
On this post I want to give you a quick demonstration on that…
For this demo, I’m using a file containing JSON (so, a less complex format than EDI or custom text files or other). To avoid inventing a JSON from scratch, I will use a file containing a JSON created using https://www.json-generator.com/ and we will use two different files:
- a small file (7 KB) containing 15 records (JSON array with 15 records generated with the above tool)
- a big file (about 7 MB) containing more than 7000 records
This is the JSON record format (single record):
{
"_id": "61b3809d892264cfad8ac86f",
"index": 0,
"guid": "b3d6a18c-eebe-4677-aba4-bdad926eea79",
"isActive": true,
"balance": "$2,491.27",
"picture": "http://placehold.it/32x32",
"age": 28,
"eyeColor": "brown",
"name": "Mays Spence",
"gender": "male",
"company": "ISOLOGIX",
"email": "maysspence@isologix.com",
"phone": "+1 (844) 571-3312",
"address": "923 Jefferson Avenue, Succasunna, Alaska, 8673",
"about": "Duis minim nostrud ex magna. Incididunt minim culpa sit nostrud aliqua commodo reprehenderit. Id pariatur tempor enim duis tempor. Consequat sit laborum mollit velit magna dolor.\r\n",
"registered": "2017-10-20T09:43:17 -02:00",
"latitude": 10.446511,
"longitude": -91.798334,
"tags": [
"dolor",
"velit",
"velit",
"do",
"duis",
"incididunt",
"occaecat"
],
"friends": [
{
"id": 0,
"name": "Mcgee Hyde"
},
{
"id": 1,
"name": "Munoz Emerson"
},
{
"id": 2,
"name": "Casey Gentry"
}
],
"greeting": "Hello, Mays Spence! You have 7 unread messages.",
"favoriteFruit": "apple"
}
The goal of the demo is the following:
- an external application sends me a complex JSON file.
- I need to parse this JSON, extract the data I need and then generate a new (and more simple) JSON response for another application (imagine it will be Dynamics 365 Business Central).
The real world scenario is always the same of the previous post: we need to parse a file containing data, then save those data into our ERP (by using APIs).
For solving this task, I will use a full low-code solution (Azure Logic Apps workflow that handles the file parsing) and then a mixed approach (same Azure Logic app workflow that now calls an Azure Function for file parsing).
Full low-code scenario
For the full low-code approach, I’ve created the following Azure Logic App workflow:
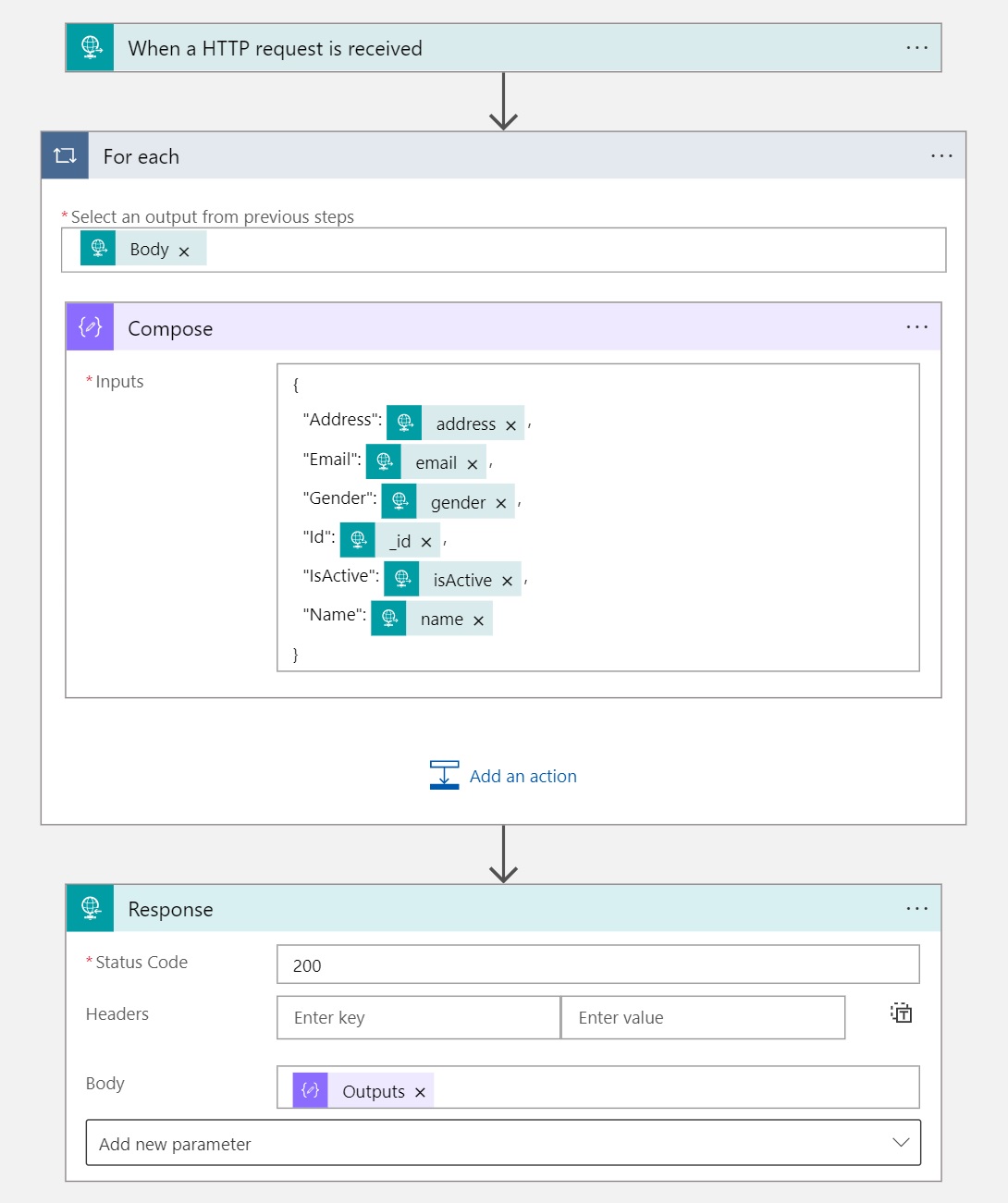
Here, when an HTTP Request containing the JSON content of the file as input is received, each record of the JSON array (file content) is retrieved (For Each control action) and for each record the Compose action creates a new JSON with the details I need (the above 6 fields only). Then a response with the new JSON response is returned (with HTTP Status Code = 200).
Now, I’m sending two HTTP request to my Azure Logic App endpoint, one with the small JSON content and one with the big JSON content.
As you can see, the workflow is triggered and the output is my formatted JSON response as defined above (the input file is correctly parsed):
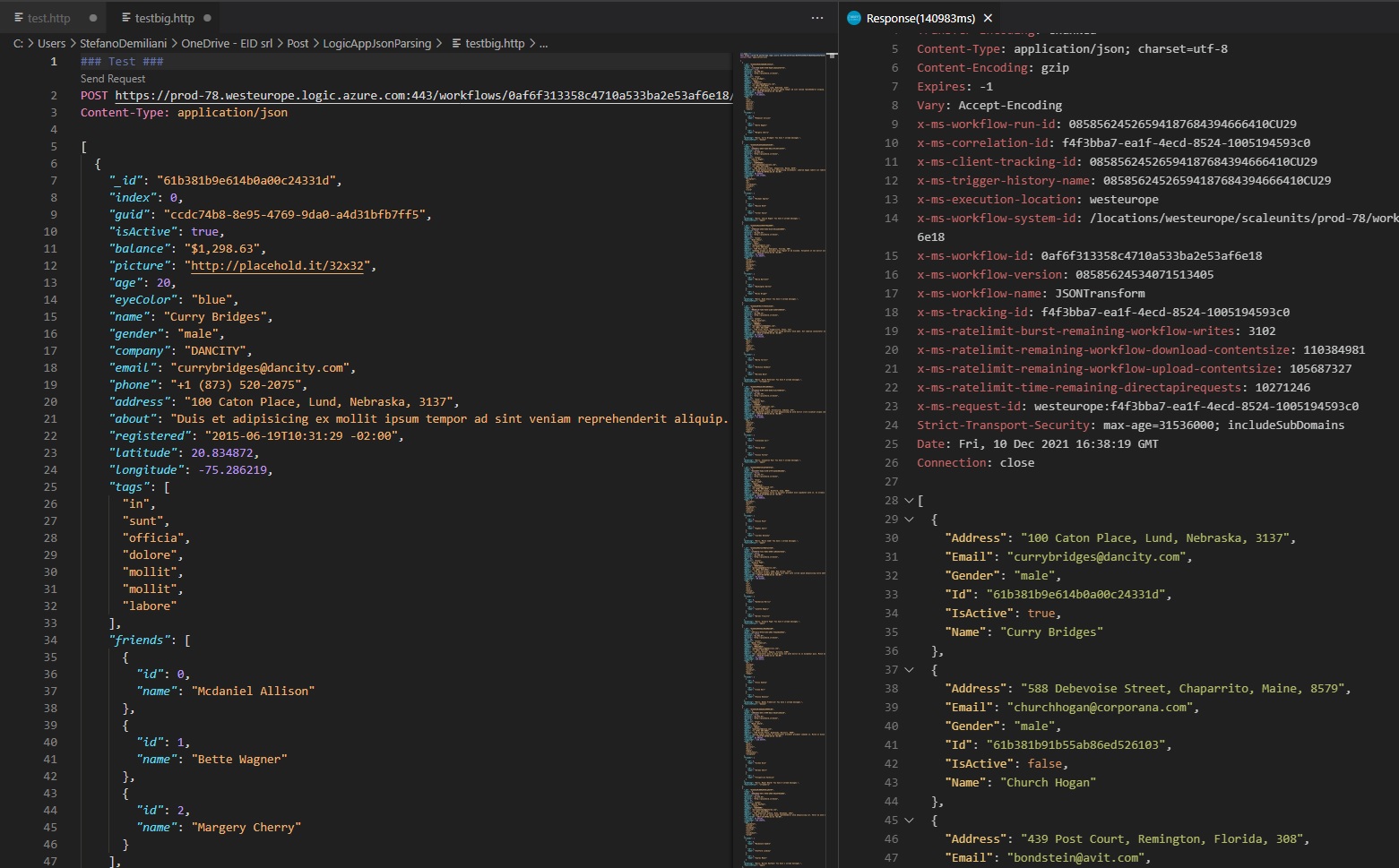
But what about the response time on these two cases?
Here is the result from the Azure Logic App log for the two executions (small file and large file):

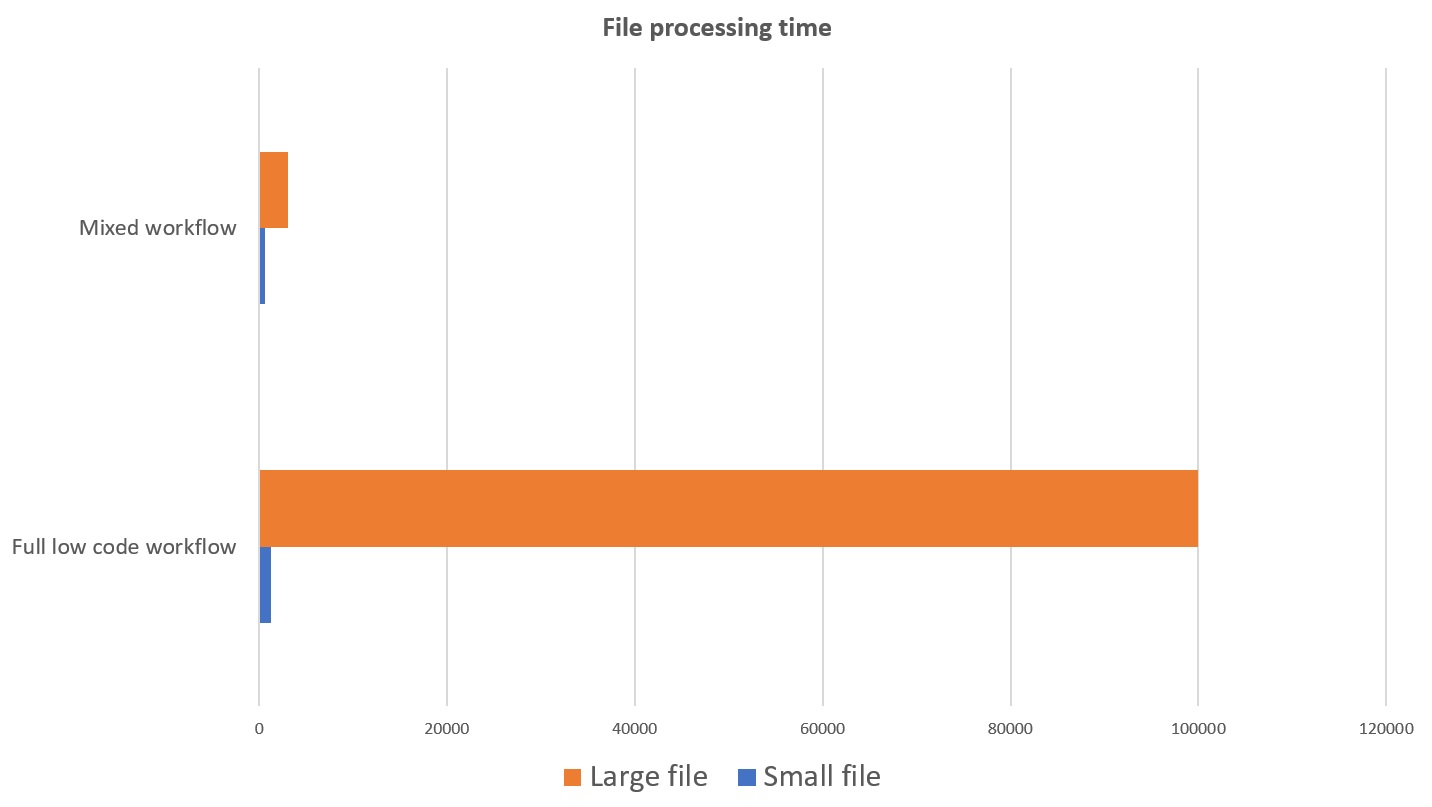
The small file is processed in about 1 second, while processing the big file requires about 2 minutes.
Mixed-approach scenario
In this scenario, I’ve created a new Azure Logic App workflow defined as follows:
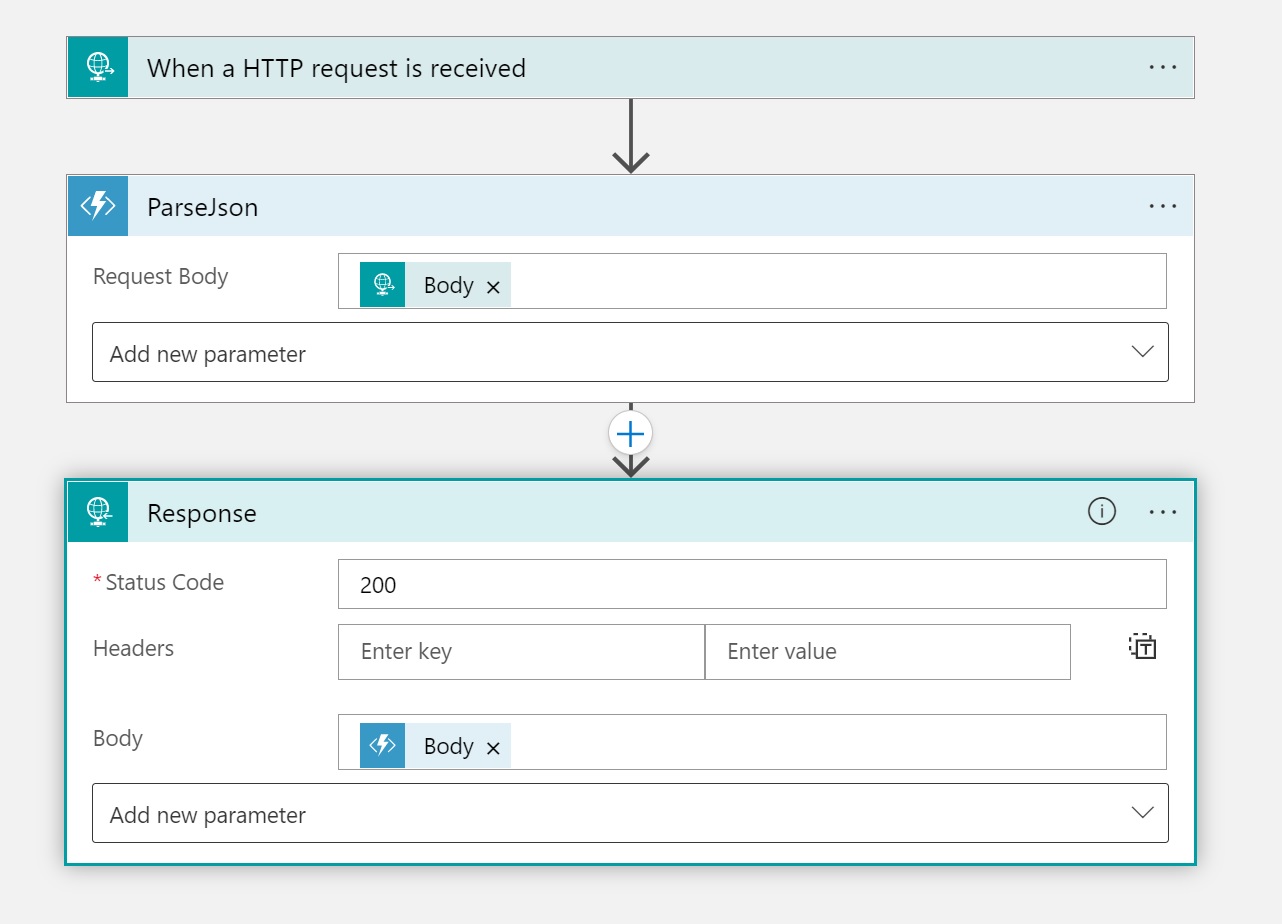
Exactly like in the previous scenario, the workflow is triggered by an HTTP request containing the JSON content of the file to process. In this case, the file processing is performed by calling an Azure Function and by passing to this function the body of the incoming request (the JSON file content in this case).
Then, the Azure Function is responsible for handling that file. The output of the Azure Function is then returned to the workflow caller by using a Response action (as before).
The Azure Function here is an HTTP Trigger function defined as follows:

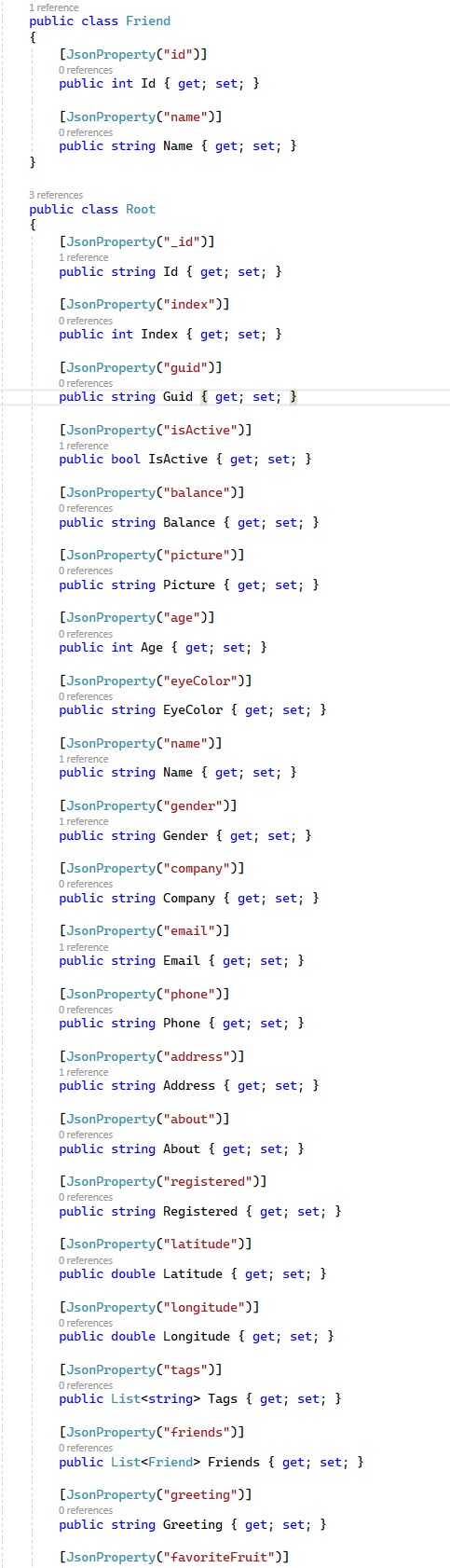
Inside this function, I’m handling the JSON file parsing as needed. I have defined some classes that maps the original JSON content:
and the desired JSON response format I want to obtain:
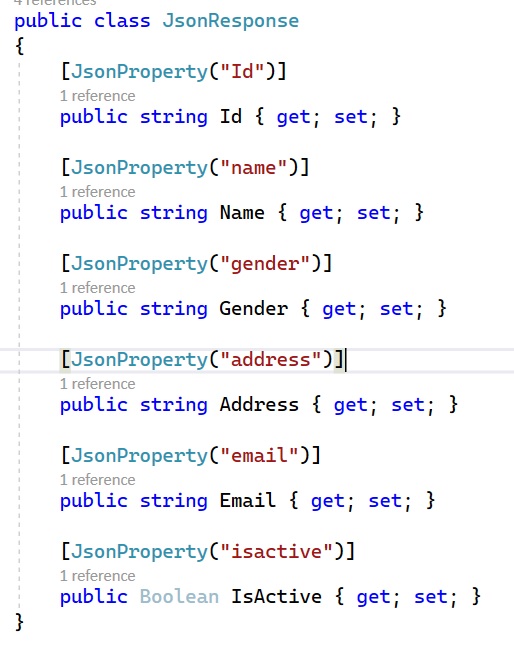
In the function body I deserialize the original JSON content, I loop through the array of records and I create the new output response. The new output message (the new JSON format I want) is then returned as response. FormJSON processing, here I’m using the Newtonsoft library (Json.NET) available via Nuget.
Now, I’m sending two HTTP request to this second Azure Logic App endpoint exactly like before, one with the small JSON content and one with the big JSON content.
What are the results now?
First call, with the small JSON content:

Second call, with the large JSON content:

I’ve executed the workflow two times for each file type, in order to have a valid result. Here the log details of the Azure Logic apps executions:

The small file is now processed in about 0.5 seconds, while the big file now requires about 3 seconds (compared to more than 1 minute in the previous scenario).
Conclusion
As you can see, for small files the gain between a full low code approach and a mixed approach is not so much (about 40%). But when the file is large and complex, the gain is tremendous.
Here for simplicity I’ve use a JSON content, but can you image if the content is something more complex to parse and handle (like EDI, PEPPOL or other formats) how more efficient can be a solution with a mixed approach?
This is just for saying (and demonstrating) that not always, even if the final result is what you want to obtain, the solution is optimal. I can understand that without writing code it could be more easy to have a result, but is this always the right approach? Are you providing a solution that performs efficiently, expecially in the cloud?
In the cloud, the architecture of a workflow is important and must be carefully evaluated, expecially if you want performance, scalability, reliability and if you want to control costs. For example, I see every day people that knows Power Automate and pretend to solve all tasks with Power Automate… but is this always the right approach? Or your solution can be extremely more efficient if you talk with a cloud developer for a specific task? And the same applies to AL language: do you want to solve all integration tasks with AL and HttpClient, or are you open to talk with someone outside the ERP box? Just start thinking on this… 🙂

Hi Stefano,
In your Full low-code scenario you don’t need the For each loop if you use the Select action.
That will make the run much faster.
More info: https://docs.microsoft.com/en-us/azure/logic-apps/logic-apps-perform-data-operations#select-action
LikeLiked by 1 person
True, thanks for the comment. But the mixed approach is more performant with large files (tested with Select after this post too) 😉
LikeLiked by 1 person