

Dynamics 365 Business Central 2021 Wave 2 release (version 19) introduces some new indexing features that you can use on your tables definitions from AL. Now you can:
- Define columnstore indexes
- Define included columns in indexes
Columnstore indexes were first introduces with SQL Server 2012. These indexes are very useful for data warehouse workloads and large tables. They can improve query performance by a factor of 10 in some cases.
Columnstore simply means a new way to store the data in the index. Instead of the normal Rowstore or b-tree indexes where the data is logically and physically organized and stored as a table with rows and columns, the data in columnstore indexes are physically stored in columns and logically organized in rows and columns. Instead of storing an entire row or rows in a page, one column from many rows is stored in that page.
This is a diagram from Microsoft that explain the feature:
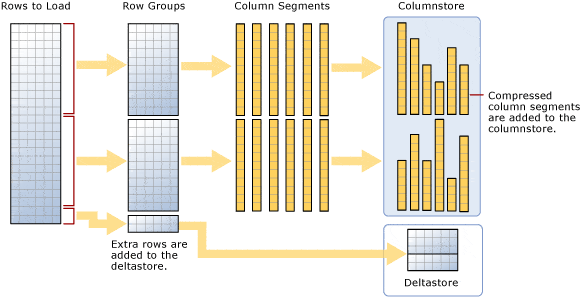
Columnstore indexes are designed for large data warehouse workloads, not normal OLTP workload tables. They’re essentially act like an in-memory compressed store that reduces the number of disk reads and increases buffer cache hit ratios. They permits you to reduce storage costs (data is compressed across columns) and having better performances.
How to create a columnstore in AL? You can do that by using the new ColumnStoreIndex table’s property, like in the following example:
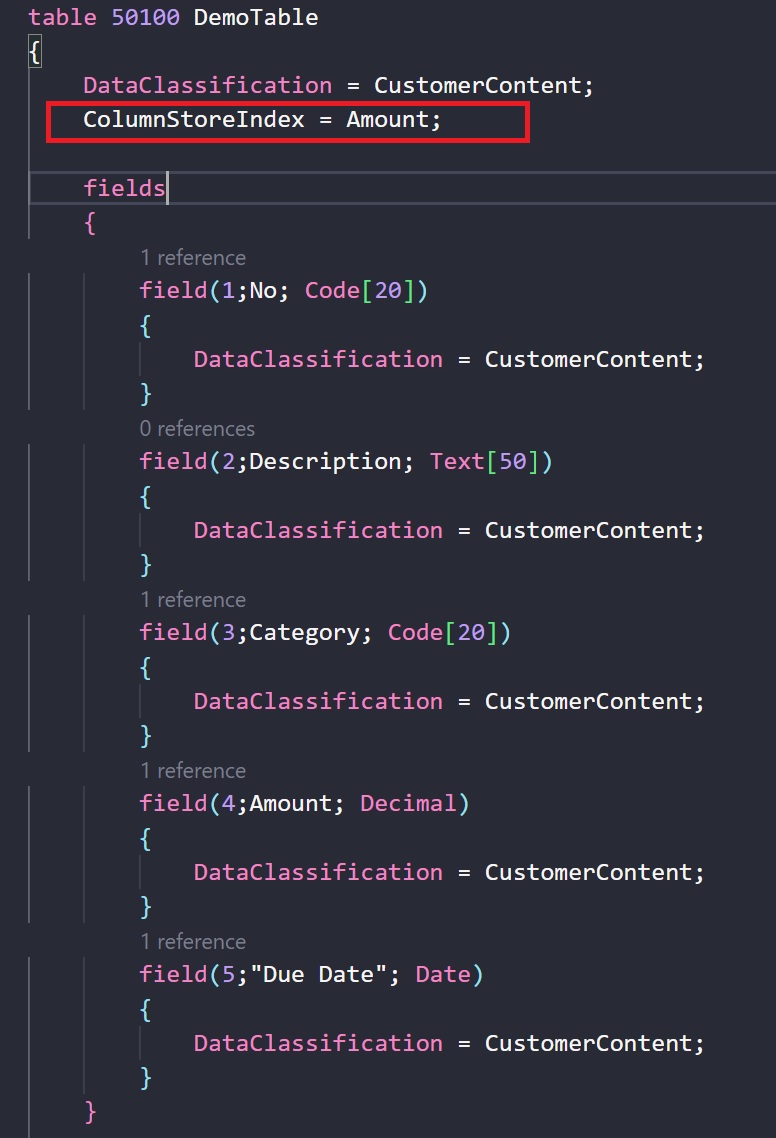
You can create 1 columnstore index per table. But just because these indexes work efficiently doesn’t mean you should always add them. Having a columnstore index on a table with few rows does not make sense in that if the table is too small, you don’t get the benefits of compression that comes with the column segments. Columnstores are also normally useful on tables with few data modifications.
Another interesting feature (that personally I love a lot!) is the possibility to add included columns in SQL indexes. To explain that, consider the following query:
SELECT CustomerNo, Department, CustomerName FROM Customer WHERE Department = 'DEP1'
If you have a secondary key on Department (non-clustered index) once you find the Customer for the selected department the engine needs to perform a “key lookup” on the clustered index of the Customer table to get the CustomerName value. If instead in your SQL table you do something like:
CREATE NONCLUSTERED INDEX NC_CustDep ON Customer(CustomerNo, Department) INCLUDE (CustomerName)
then all the information you need is available in the leaf level of the non-clustered index. Only by seeking in the non-clustered index and finding your Customers for a given Department, now you have all the necessary information, and the key lookup for each Customer record found in the index is no longer necessary. In this case the query optimizer will solely use the non-clustered index to return the requested data of the query and the query is much more performant.
How can you add included columns on indexes in AL?
You can do like in the following example:

On many scenarios, this helps on improving your queries and on reducing the size of the table. Instead of adding more columns as index keys, use included columns to extend the non-clustered index.
Please remember that there’s no a general rule on how and where to use them, but only recommendations. I think that you always have to test your queries with your indexes to determine the best strategy.
IncludedFields is where I personally have experienced the best gains. Please also remember that you can change the IncludedFields list of fields from version N to version N+1 of your extension, this is not a breaking change. So you can do something like the following in a next version:
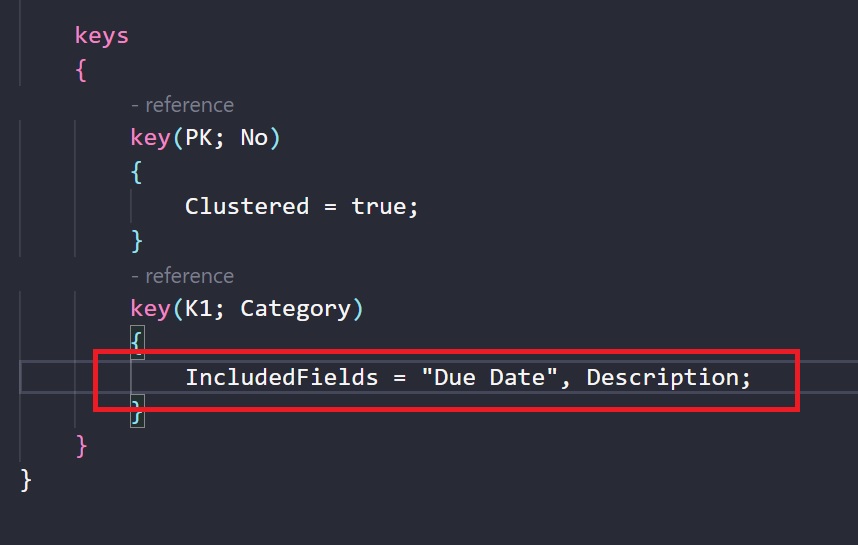
Here, I’ve added a new field in my included columns for my non-clustered index K1.
Included columns are useful also for optimizing partial records scenarios. I suggest to give these new features a try 😉

Hi Stefano,
Do you have any experience the usage of Database missing indexes menu? I look for the proper way to manage the content of this list. What should be the best way to “consume” this content? I think it would be mindless to create any suggestion without deeper investigation.
Nevertheless, my feeling is that there are certain reasons to pop up suggestions here.
Thanks in advance!
LikeLike
The Database Missing Indexes page shows indexes that the SQL query optimizer suggests as possible addition to the database. The optimizer gives an indication based on the executed queries on tables. I think it’s a nice view to check when you want to optimize performances, but it’s not absolutely true that you need always to follow the suggestions.
LikeLike